<aside> 📘 Series:
Beginner’s Guide on Recurrent Neural Networks with PyTorch
A Brief Introduction to Recurrent Neural Networks
Illustrated Guide to Transformers- Step by Step Explanation
How to code The Transformer in PyTorch
</aside>
Transformers are taking the natural language processing world by storm. These incredible models are breaking multiple NLP records and pushing the state of the art. They are used in many applications like machine language translation, conversational chatbots, and even to power better search engines. Transformers are the rage in deep learning nowadays, but how do they work? Why have they outperform the previous king of sequence problems, like recurrent neural networks, GRU’s, and LSTM’s? You’ve probably heard of different famous transformers models like BERT, GPT, and GPT2. In this post, we’ll focus on the one paper that started it all, “Attention is all you need”.
Check out the link below if you’d like to watch the video version instead.
https://www.youtube.com/watch?v=4Bdc55j80l8&embeds_widget_referrer=https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0&embeds_referring_euri=https://cdn.embedly.com/&embeds_referring_origin=https://cdn.embedly.com&source_ve_path=OTY3MTQ&feature=emb_imp_woyt
To understand transformers we first must understand the attention mechanism. The Attention mechanism enables the transformers to have extremely long term memory. A transformer model can “attend” or “focus” on all previous tokens that have been generated.
Let’s walk through an example. Say we want to write a short sci-fi novel with a generative transformer. Using Hugging Face’s Write With Transformer application, we can do just that. We’ll prime the model with our input, and the model will generate the rest.
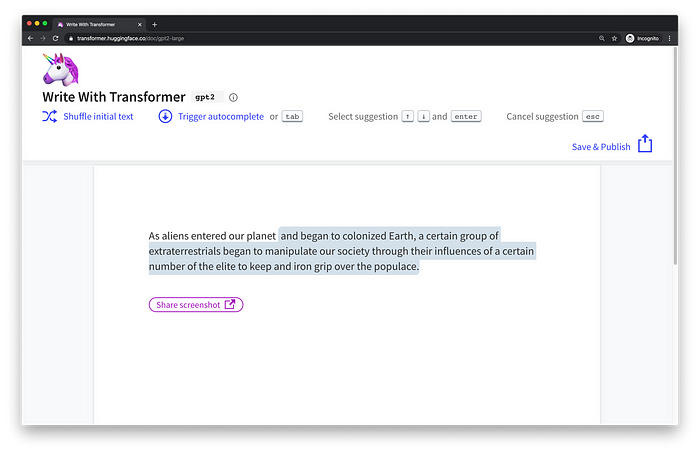
Our input: “As Aliens entered our planet”.
Transformer output: “and began to colonized Earth, a certain group of extraterrestrials began to manipulate our society through their influences of a certain number of the elite to keep and iron grip over the populace.”
Ok, so the story is a little dark but what’s interesting is how the model generated it. As the model generates the text word by word, it can “attend” or “focus” on words that are relevant to the generated word. The ability to know what words to attend too is all learned during training through backpropagation.

Attention mechanism focusing on different tokens while generating words 1 by 1
Recurrent neural networks (RNN) are also capable of looking at previous inputs too. But the power of the attention mechanism is that it doesn’t suffer from short term memory. RNN’s have a shorter window to reference from, so when the story gets longer, RNN’s can’t access words generated earlier in the sequence. This is still true for Gated Recurrent Units (GRU’s) and Long-short Term Memory (LSTM’s) networks, although they do a bigger capacity to achieve longer-term memory, therefore, having a longer window to reference from. The attention mechanism, in theory, and given enough compute resources, have an infinite window to reference from, therefore being capable of using the entire context of the story while generating the text.

Hypothetical reference window of Attention, RNN’s, GRU’s & LSTM’s
The attention mechanism’s power was demonstrated in the paper “Attention Is All You Need”, where the authors introduced a new novel neural network called the Transformers which is an attention-based encoder-decoder type architecture.
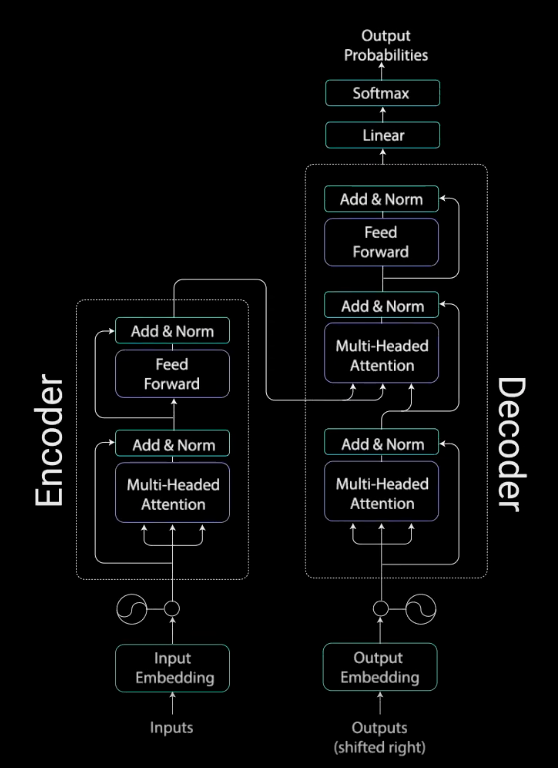
Transformer Model