<aside> 📘 Series:
Beginner’s Guide on Recurrent Neural Networks with PyTorch
A Brief Introduction to Recurrent Neural Networks
Illustrated Guide to Transformers- Step by Step Explanation
How to code The Transformer in PyTorch
</aside>
Could The Transformer be another nail in the coffin for RNNs?
Doing away with clunky for-loops, the transformer instead finds a way to allow whole sentences to simultaneously enter the network in batches. With this technique, NLP reclaims the advantage of Python’s highly efficient linear algebra libraries. This time-saving can then be spent deploying more layers into the model.
So far, it seems the result from transformers is faster convergence and better results. What’s not to love?
My personal experience with this technique has been highly promising. I trained on 2 million French-English sentence pairs to create a sophisticated translator in only three days.
You can play with the model yourself on language translating tasks if you go to my implementation on Github here. Also, you can look out for my next post on the FloydHub blog, where I share my journey building the translator and the results.
Or, even better, you could build one yourself. Here’s the guide on how to do it, and how it works.
Ready to build, train, and deploy AI? Get started with FloydHub's collaborative AI platform for freeTry FloydHub for free
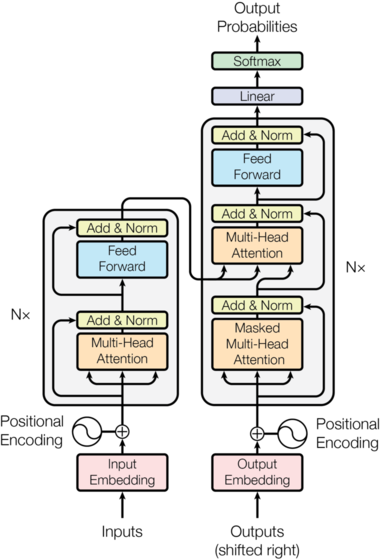
The diagram above shows the overview of the Transformer model. The inputs to the encoder will be the English sentence, and the 'Outputs' entering the decoder will be the French sentence.
In effect, there are five processes we need to understand to implement this model: