<aside> 📘
Series:
In CockroachDB v21.2 we introduced a new admission control and resource allocation subsystem, and in our most recent release (v22.1) we’ve made substantial improvements. In this blog post, we’ll cover the improvements made to admission control, including a description of the generally applicable mechanisms we developed, which should be relevant for any distributed transactional database with multi-node transactions.
These mechanisms include hybrid token and slot based allocation mechanisms, and dynamic adjustment of slot and token counts, in order to control both CPU and storage resource allocation. The mechanisms include support for multi-tenant performance isolation and prioritization within a tenant, and priority adjustment to reduce inversion due to transactions holding locks (for transaction serializability). The multi-stage and distributed execution of transactions creates difficulties when dealing with transactions with aggressive deadlines, for which we have developed an epoch-LIFO (last in first out) mechanism.
CockroachDB is implemented in Go, and for that reason we’re unable to make CPU (goroutine) scheduler changes – in the blog we’ll discuss how we dealt with this limitation and shifted significant queueing from the goroutine scheduler to the admission control queues, while achieving high CPU utilization.
The admission control system decides when work submitted to a system begins executing, and is useful when there is some resource (e.g. CPU) that is fully utilized, and you need to decide how to allocate this fully utilized resource. Prior to adding admission control to CockroachDB we experienced various forms of bad behavior in cases of overload, which, in the extreme, could lead to node failures, due to nodes being unable to do the work to prove that they were alive. There was also a desire to make informed decisions that would allow (a) higher priority queries to not suffer degradation, and (b) in the case of the multi-tenant version of CockroachDB deployed for the CockroachDB Serverless, provide performance isolation between tenants.
The current implementation focuses on node-level admission control, for CPU and storage IO (specifically writes) as the bottleneck resources. The focus on node-level admission control is based on the observation that large scale distributed databases may be provisioned adequately at the aggregate level, but since they have stateful nodes, individual node hotspots can develop that can last for some time (until rebalancing). Such hotspots should not cause failures or degrade service for important work, or unfairly for tenants that are not responsible for the hotspot.
We focus on two bottleneck resources at a node, CPU, and storage write throughput.
For CPU, the goal is to shift queueing from inside the CPU scheduler (Go’s goroutine scheduler), where there is no differentiation, into admission queues that can differentiate. This must be done while allowing the system to have high peak CPU utilization.
For storage, CockroachDB uses a log-structured merge tree (LSM) storage layer called Pebble that resembles RockDB and LevelDB in many ways. A write throughput bottleneck manifests itself as an increase in read amplification because the LSM is unable to compact fast enough. The goal is to limit the admission of write work such that we can maintain read amplification at or below some configurable threshold R_amp (default value is 20). We have previously observed overload situations where read amplification has reached 1000, which slows down reads significantly.
Admission queues use the tuple (tenant, priority, transaction start time), to order work that is waiting to be admitted. There is coarse-grained fair sharing of resources across tenants (for a shared multi-tenant cluster). Priority is used within a tenant, and allows for starvation, in that if higher priority work is always consuming all resources, the lower priority work will wait forever. The transaction start time is used within a priority, and typically gives preference to earlier transactions, i.e., it is FIFO (first in first out) based on transaction start time. We will later discuss LIFO (last in first out) in the context of the epoch-LIFO scheme.
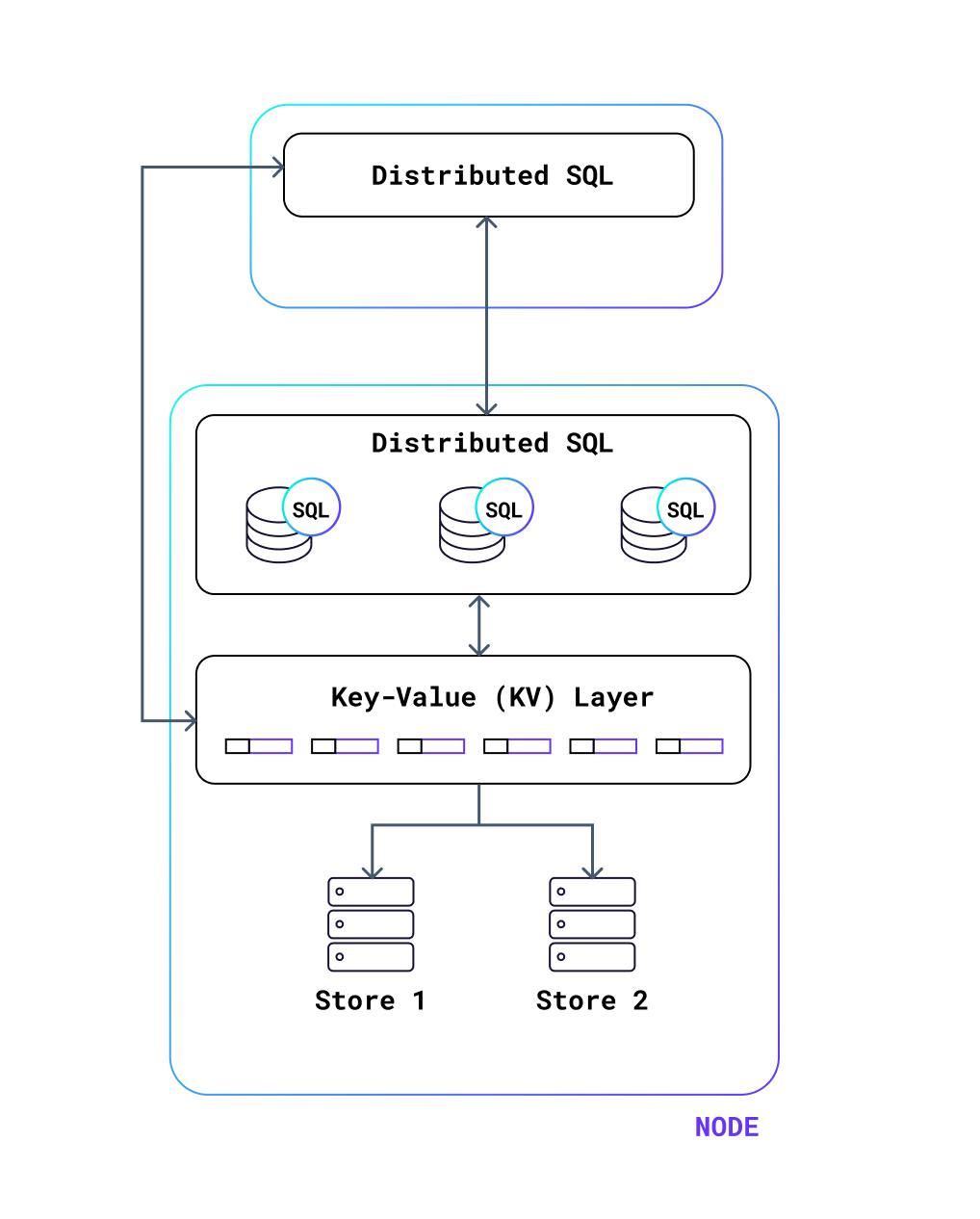
The following diagram shows an abstracted version of the system architecture. The distributed-SQL layer communicates via streams of messages with the same layer at other nodes – the layer on the top is acting as the root of the execution tree in this example. The distributed-SQL layer provides small units of work to the local or remote key-value (KV) layer, executed in a request-response manner. The KV layer executes read and write work against the storage layer, and there can be multiple stores on a node.
The request-response nature of the KV layer provides an entry-exit point for each piece of work. The response processing in the Distributed-SQL layer does not have an exit point: sometimes it may end with sending a message back to the root, and at other times it will do some processing and buffer the result. Where that processing ends can vary based on the operators involved in the SQL query. Both the KV and Distributed-SQL layers can consume substantial CPU, and which consumes more of the CPU depends on the mix of queries being executed by the system. Additionally, even though the size of work in processing a request at the KV layer or a response in the distributed-sql layer is small (roughly bounded by a few milliseconds), there is extreme heterogeneity in actual resource consumption.
Since we are unable to make changes to Go’s CPU (goroutine) scheduler, we intercept CPU bound work with multiple queues in the following diagram: KV-Storage CPU, Response from KV, Response from DistSQL. Additionally, KV work that writes to the storage layer is intercepted in per-store write queues (shown in green), since the utilization of different stores can vary.
Note that a single transaction will submit many units of work to these queues over its lifetime. The number varies based on the number and complexity of statements in the transaction, and how much data it processes.