<aside> 📘
Anthropic/Claude Series:
Building Effective AI Agents \ Anthropic
Effective context engineering for AI agents \ Anthropic
Effective harnesses for long-running agents \ Anthropic
How we built our multi-agent research system \ Anthropic
Code execution with MCP: building more efficient AI agents \ Anthropic
Demystifying evals for AI agents \ Anthropic
</aside>
The capabilities that make agents useful also make them difficult to evaluate. The strategies that work across deployments combine techniques to match the complexity of the systems they measure.
Good evaluations help teams ship AI agents more confidently. Without them, it’s easy to get stuck in reactive loops—catching issues only in production, where fixing one failure creates others. Evals make problems and behavioral changes visible before they affect users, and their value compounds over the lifecycle of an agent.
As we described in Building effective agents, agents operate over many turns: calling tools, modifying state, and adapting based on intermediate results. These same capabilities that make AI agents useful—autonomy, intelligence, and flexibility—also make them harder to evaluate.
Through our internal work and with customers at the frontier of agent development, we’ve learned how to design more rigorous and useful evals for agents. Here's what's worked across a range of agent architectures and use cases in real-world deployment.
An evaluation (“eval”) is a test for an AI system: give an AI an input, then apply grading logic to its output to measure success. In this post, we focus on automated evals that can be run during development without real users.
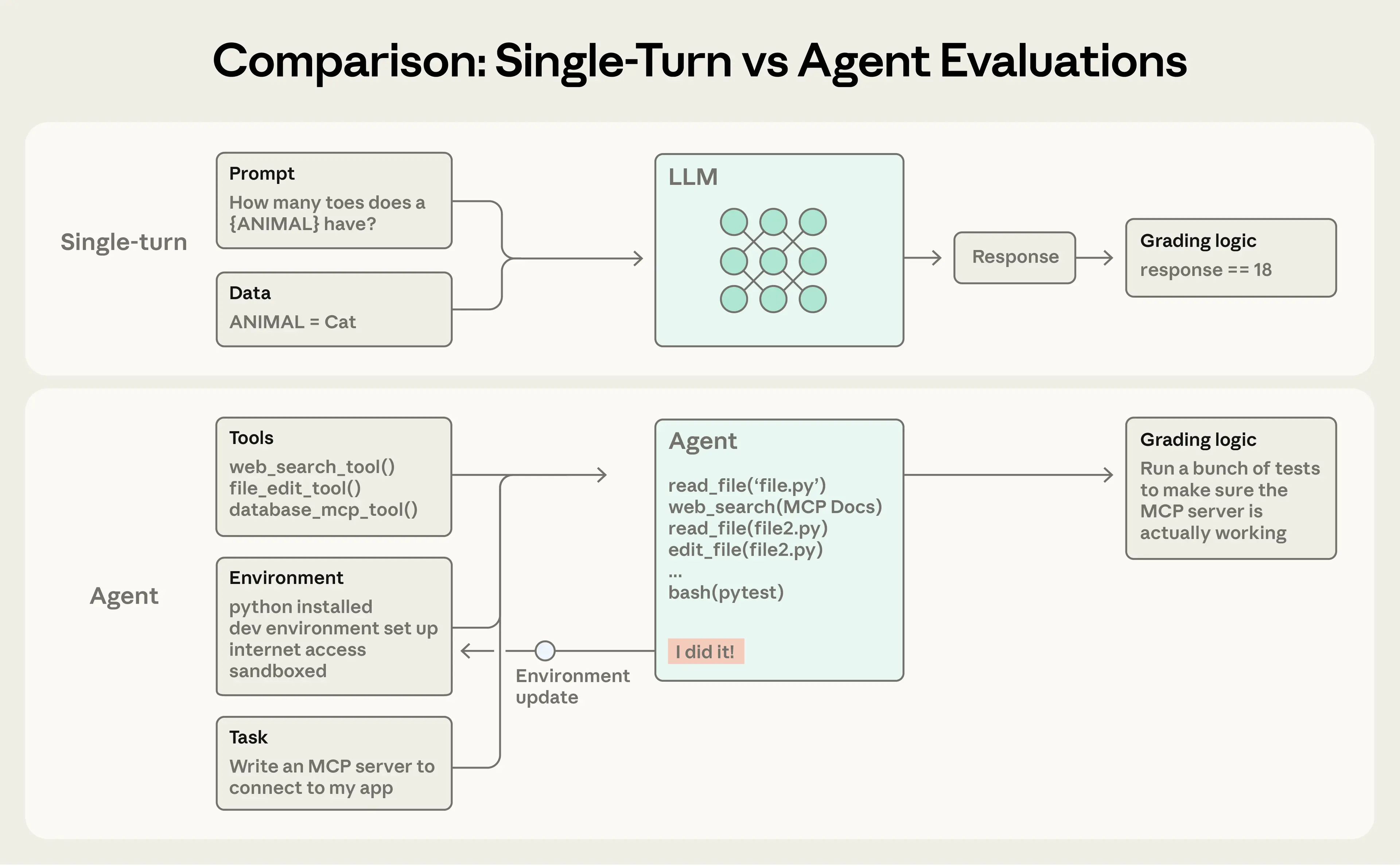
Single-turn evaluations are straightforward: a prompt, a response, and grading logic. For earlier LLMs, single-turn, non-agentic evals were the main evaluation method. As AI capabilities have advanced, multi-turn evaluations have become increasingly common.
In a simple eval, an agent processes a prompt, and a grader checks if the output matches expectations. For a more complex multi-turn eval, a coding agent receives tools, a task (building an MCP server in this case), and an environment, executes an "agent loop" (tool calls and reasoning), and updates the environment with the implementation. Grading then uses unit tests to verify the working MCP server.
Agent evaluations are even more complex. Agents use tools across many turns, modifying state in the environment and adapting as they go—which means mistakes can propagate and compound. Frontier models can also find creative solutions that surpass the limits of static evals. For instance, Opus 4.5 solved a 𝜏2-bench problem about booking a flight by discovering a loophole in the policy. It “failed” the evaluation as written, but actually came up with a better solution for the user.
When building agent evaluations, we use the following definitions:
{kind=link}