<aside> 📘
Series:
Context Engineering for AI Agents: Lessons from Building Manus
</aside>
At the very beginning of the Manus project, my team and I faced a key decision: should we train an end-to-end agentic model using open-source foundations, or build an agent on top of the in-context learning abilities of frontier models?
Back in my first decade in NLP, we didn't have the luxury of that choice. In the distant days of BERT (yes, it's been seven years), models had to be fine-tuned—and evaluated—before they could transfer to a new task. That process often took weeks per iteration, even though the models were tiny compared to today's LLMs. For fast-moving applications, especially pre–PMF, such slow feedback loops are a deal-breaker. That was a bitter lesson from my last startup, where I trained models from scratch for open information extraction and semantic search. Then came GPT-3 and Flan-T5, and my in-house models became irrelevant overnight. Ironically, those same models marked the beginning of in-context learning—and a whole new path forward.
That hard-earned lesson made the choice clear: Manus would bet on context engineering. This allows us to ship improvements in hours instead of weeks, and kept our product orthogonal to the underlying models: If model progress is the rising tide, we want Manus to be the boat, not the pillar stuck to the seabed.
Still, context engineering turned out to be anything but straightforward. It's an experimental science—and we've rebuilt our agent framework four times, each time after discovering a better way to shape context. We affectionately refer to this manual process of architecture searching, prompt fiddling, and empirical guesswork as "Stochastic Graduate Descent". It's not elegant, but it works.
This post shares the local optima we arrived at through our own "SGD". If you're building your own AI agent, I hope these principles help you converge faster.
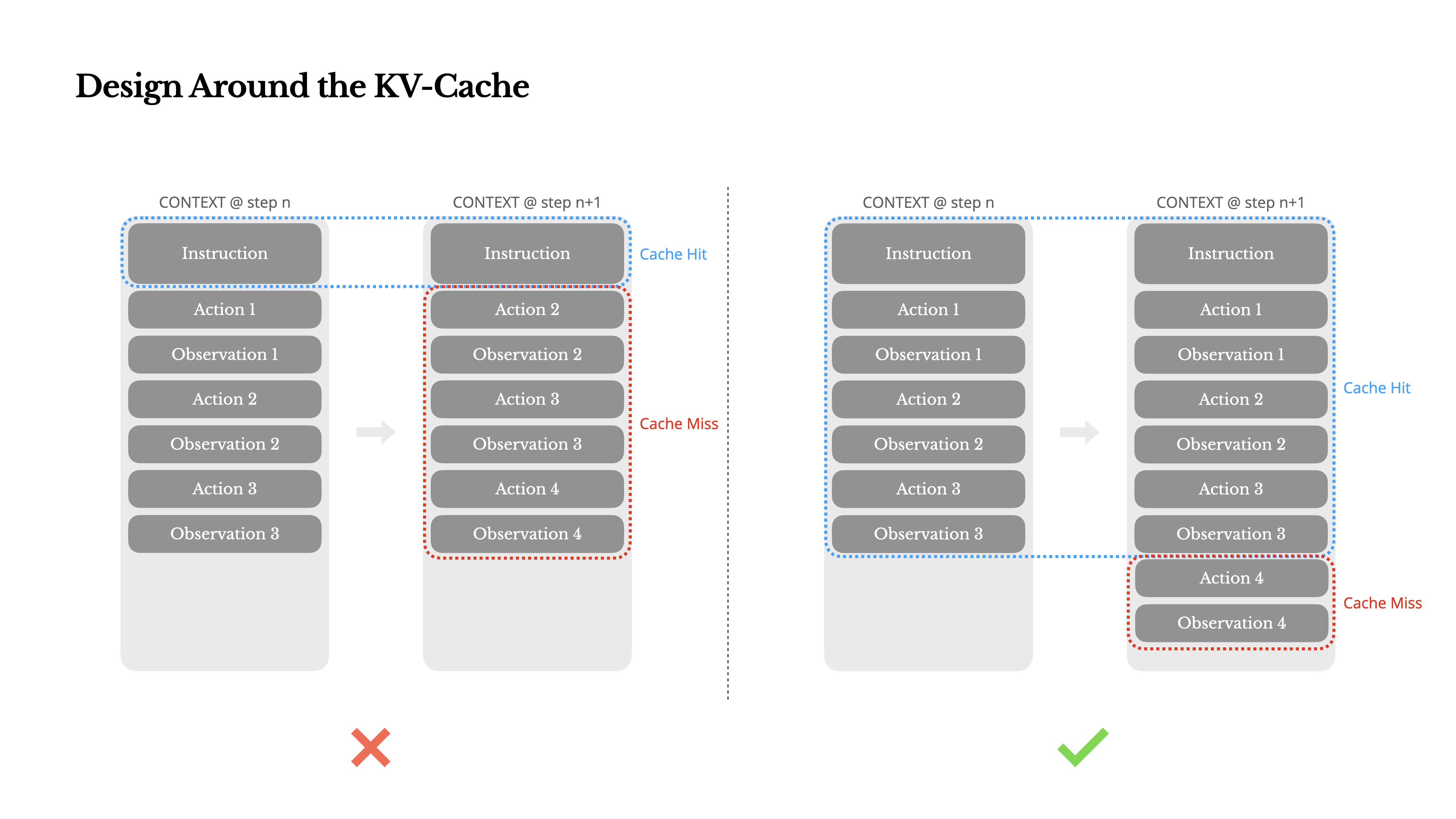
If I had to choose just one metric, I'd argue that the KV-cache hit rate is the single most important metric for a production-stage AI agent. It directly affects both latency and cost. To understand why, let's look at how a typical agent operates:
After receiving a user input, the agent proceeds through a chain of tool uses to complete the task. In each iteration, the model selects an action from a predefined action space based on the current context. That action is then executed in the environment (e.g., Manus's virtual machine sandbox) to produce an observation. The action and observation are appended to the context, forming the input for the next iteration. This loop continues until the task is complete.
As you can imagine, the context grows with every step, while the output—usually a structured function call—remains relatively short. This makes the ratio between prefilling and decoding highly skewed in agents compared to chatbots. In Manus, for example, the average input-to-output token ratio is around 100:1.
Fortunately, contexts with identical prefixes can take advantage of KV-cache, which drastically reduces time-to-first-token (TTFT) and inference cost—whether you're using a self-hosted model or calling an inference API. And we're not talking about small savings: with Claude Sonnet, for instance, cached input tokens cost 0.30 USD/MTok, while uncached ones cost 3 USD/MTok—a 10x difference.
From a context engineering perspective, improving KV-cache hit rate involves a few key practices:
Additionally, if you're self-hosting models using frameworks like vLLM, make sure prefix/prompt caching is enabled, and that you're using techniques like session IDs to route requests consistently across distributed workers.
As your agent takes on more capabilities, its action space naturally grows more complex—in plain terms, the number of tools explodes. The recent popularity of MCP only adds fuel to the fire. If you allow user-configurable tools, trust me: someone will inevitably plug hundreds of mysterious tools into your carefully curated action space. As a result, the model is more likely to select the wrong action or take an inefficient path. In short, your heavily armed agent gets dumber.
A natural reaction is to design a dynamic action space—perhaps loading tools on demand using something RAG-like. We tried that in Manus too. But our experiments suggest a clear rule: unless absolutely necessary, avoid dynamically adding or removing tools mid-iteration. There are two main reasons for this: